News
Stay up to speed with the latest news and updates on what happens within AI Sweden and in our projects.
AI Sweden’s partner network continues to grow
We welcome Swedac, Trafikverket, InooLabs intric and Manomotion as new partners of AI Sweden. With their addition, AI Sweden’s partner network continues to grow with organizations spanning academia...

Introducing the new cohort for Eye for AI
The talent program, Eye for AI - Graduate Program for Future Leaders in AI, is back with a new cohort! This time around, we welcome four talents, both national and international, who will be...

AI Sweden launches an AI strategy for Sweden
Using AI is necessary for solving key societal challenges, staying competitive, and in general preserving and developing a democratic society with a high quality of life. The objective of An AI...

The Impact report 2023 is here
Last year in figures and stories | This year, we celebrate five years of accelerating the use of AI for the benefit of our society, our competitiveness, and for everyone living in Sweden. We've...

IBM joins AI Sweden
IBM is joining AI Sweden’s partner network. Together with over 120 partners from both the public and private sectors as well as academia, the mission is to accelerate the use of AI in Sweden for the...

The AI Sweden network is growing
We welcome Stena, Red Hat, Skolverket, Familjens Jurist, SSF Service, Lidingö Stad, Swedish Defence University, and Carbonzero as new partners of AI Sweden. With their addition, AI Sweden’s partner...
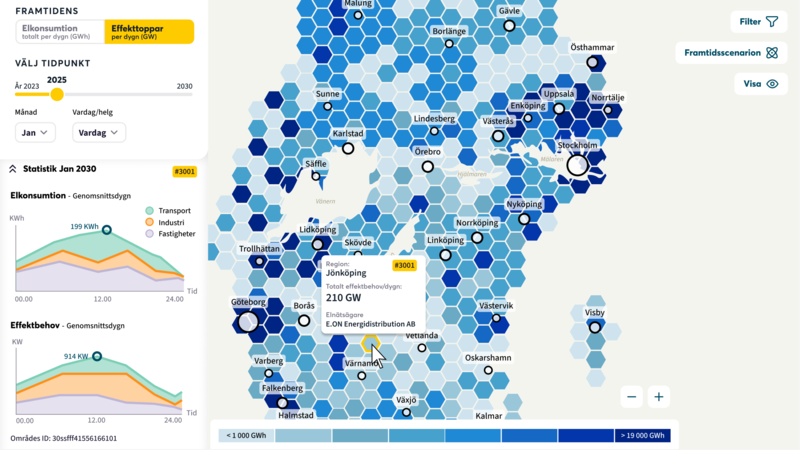
Shared data describes the Swedish electrical system in a new way
What will Sweden's future energy system look like? Where will electricity be produced? Where will it be used, and when? The answers to these questions are what Behovskartan ('The needs map') aims to...

Swedish Government establishes new AI commission
The Swedish government has announced an AI Commission, focusing on a pivotal question: How can artificial intelligence bolster Swedish welfare and competitiveness? Among its members is Martin Svensson...

Significant new initiatives to propel Sweden's AI development
AI Sweden and its partners are launching two groundbreaking AI initiatives that will be pivotal for Sweden's competitive edge and the ability to deliver high-quality societal services. These...
AI Sweden partners with Unity Health Toronto for healthcare advancements
AI has become a crucial technology within the healthcare industry, demonstrating its impact notably at Unity Health Toronto's hospitals in Canada. As one example, more than 20 percent fewer patients...

Open release of the first large Nordic language model GPT-SW3
AI Sweden now releases the first large Nordic language model, GPT-SW3. It is available as an open model for businesses and organizations to use in their products and services. The model provides...

Strengthening the infrastructure and expanding opportunities at AI Sweden’s Data Factory
Since its establishment, the equipment that’s an important part of AI Sweden’s Data Factory has been located in Gothenburg. The team is now planning to place hardware at other nodes as well.

Let AI Sweden’s Young Talents accelerate your AI journey
In August, AI Sweden's Young Talent program 2023/2024 hit the ground running. The 14 participants are now a month into their training at AI Sweden. In January, they are ready to take on project work...

Three new members elected to the steering committee for AI Sweden
Lars Stugemo, Linda Leopold and Patrik André have been elected as new members of the steering committee by the Partner Forum.

AI Council develops recommendations for accelerated AI development in Swedish municipalities
Representatives from 12 of the country's municipalities have come together to present a series of recommendations for initiatives aimed at enhancing the ability of Swedish municipalities to utilize...
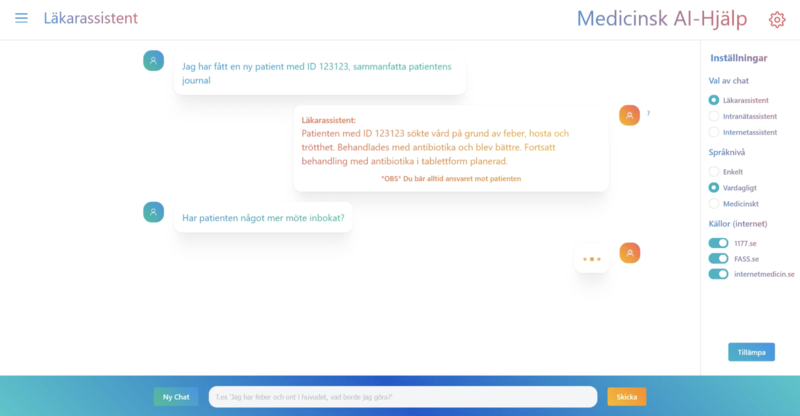
Validating generative text models for real-world use cases
Over the summer, Västra Götalandsregionen (VGR), Chalmers, Microsoft and Zenseact joined forces in AI Sweden's GPT Summer Internship Program and hosted eight graduate students. Over a period of ten...

Over 150 leaders at Future of Democracy Summit
On the 29-30 of May, the third edition of Future of Democracy Summit was held in Gothenburg. More than 150 leaders and decision-makers from academia, industry, media, public sector and civil society...

Welcoming 13 new partners to the AI Sweden network
We welcome Amazon Web Services, City of Stockholm, EdAider, Fictive Reality, Högskolan Väst, Kungliga Biblioteket, Natur & Kultur, Neko Health, Repli5, SICSAI, Silo AI, The Swedish Law and Informatics...

AI Sweden joins forces with three Swedish universities and launches AI course for executives
AI for Executives is a six-day program designed for leaders and senior executives, developed by the executive education units at Stockholm University, Uppsala University, and Gothenburg University, in...
18 new startups join the Swedish AI Startup Landscape
The Swedish AI Startup Landscape has been updated and we are now welcoming 18 new startups!

AI Sweden’s participation in the EU-US Trade and Technology Council meeting
Daniel Gillblad, Co-Director Scientific Vision at AI Sweden, joined U.S. Secretary of State Anthony Blinken, EU Commissioner Margrethe Vestager and others to discuss transatlantic trade and generative...

Putting AI on the map with the AI Maturity Assessment
What are the ways to leverage AI for advancing your organization, and how can you determine the best starting point? This is where AI Sweden’s AI Maturity Assessment comes in, a process that helps...

AI Sweden Nomination Committee appointed
New host organizations in the North and South Nodes of AI Sweden
AI Sweden welcomes two new host organizations for its North and South Nodes: LTU Business in the North and Innovation Skåne in the South.